Should faculty use AI for feedback and assessment?
Short answer: No. Long answer... keep reading.


If you’re like me, you have probably been pretty focused on students’ use of GenAI. But another layer of complexity is coming into view: the implications and ethics of our own GenAI use, particularly when it comes to feedback and assessment.
On the one hand, feedback and assessment seem ripe for disruption, if not automation. For decades, faculty have wrestled with how to get students to actually read feedback, how to ensure that feedback is actionable and advances learning rather than merely justifies a grade. We worry about the way assessment entrenches inequality, dampens intrinsic motivation, and reduces teaching to test prep.
Then there’s our teaching loads, and the impossible number of student projects that need our attention and time.
Given all of that, the appeal of GenAI makes a certain amount of sense. Maybe a synthetic TA is better than no TA. Maybe GenAI can make assessment more consistent and feedback more thorough, taking messy human fallibility out of the picture, boosting us beyond the time constraints that reduce our feedback to checking boxes on rubrics.
But—and this is a word I will return to throughout this post— even OpenAI’s own terms of service caution against using ChatGPT for these purposes. They explicitly prohibit using AI output for decisions that could have material impacts, including in education, and warn against automating in “sensitive areas” without human involvement and review.
University guidance and professional organizations also raise red flags, especially around student data privacy. At SF State, our guidance notes that even when FERPA requirements are technically met, students may experience the uploading of their work as a violation of trust and a threat to their data privacy. Indeed, this article highlights that any use of AI assistance for feedback and assessment may put your students at risk.
Are there best practices to guide us? After reading several university webpages and professional organization recommendations, here’s what I’ve got:
Maintain a human-in-charge approach on every student paper or project, and at every stage of the process;
Don’t violate students’ data privacy or FERPA laws by uploading student work to GenAI platforms or using the AI features that now show up in our workspaces; be extremely cautious with AI-enabled Chrome extensions;
Be transparent with students about your GenAI use; allow students to opt-out; recognize that your use of GenAI may undermine the student-teacher relationship and weaken the value of education in students’ eyes;
Keep in mind environmental costs, bias, privileging of Western epistemologies and languages, hallucinations, and the GenAI tendency toward surface-level, shallow “analysis”.
Do these best practices mean you can’t use GenAI for feedback and assessment? My short answer: correct. Given so many ethical issues, using GenAI for this purpose is a bad idea; addressing the ethical issues will undercut any time saved.

A longer answer….
Of course, there is always more to the story.
For decades, researchers have experimented with using machines to provide various kinds of assessment and various kinds of feedback on various kinds of student writing (including writing to demonstrate content learning, and writing to demonstrate literacy and rhetorical skills).
Most of these experiments couldn’t get past technical limitations and pedagogical challenges. Machines *might* accurately score student essays and *might* deliver feedback, but these results were too reductive or mechanistic to be of pedagogical value.

But the emergence of GenAI has created renewed interest in the possibilities for automated feedback and assessment. With GenAI, the thinking goes, perhaps we can now automate in a more personalized / authentic way?
After reading .0001% of the emerging research on this topic, and weeding out studies that are AI-generated fakes (heavy sigh), here’s a quick summary:
This study compared LLM and human scoring of students’ written responses to science questions. The authors found only “modest” differences between human and ChatGPT assessments. They acknowledge that LLMs used shortcuts like spotting keywords and weren’t good at assessing understanding, but also found that incorporating high-quality analytical rubrics designed to reflect human grading logic can mitigate this gap and enhance LLMs’ scoring accuracy. In the end, though, they caution that aligning LLMs for the purpose of assessment is a nuanced, complex undertaking.
This study compared GenAI and human feedback. They found that GenAI does slightly worse than humans, but conclude that ChatGPT has potential …given tradeoffs between quality and time.

But, this raised questions for me. Does more frequent or copious but slightly worse feedback actually help students? I think my students would reject the idea of receiving a high volume of lower-quality assessments or feedback. They already feel that interpreting teacher comments is too hard. Given the choice, I’m guessing that they would prefer smaller amounts of slower, accurate feedback over quick, abundant feedback that isn’t as helpful.
Another interesting tidbit from this study: ChatGPT’s shortcomings varied by the quality of the student writing. With higher-quality student writing, ChatGPT’s feedback got less accurate; when the quality of the student writing was low, ChatGPT struggled to maintain a supportive tone, to address the student in a developmentally sound way. In other words, ChatGPT struggled to provide feedback on higher-order rhetorical thinking, and wasn’t good at providing support for students who needed the most help. Which is a fun way of saying, maybe feedback isn’t so outsourceable after all?
Other takeaways from the research front:
Automating feedback and grading may undermine the human relationships that are central to authentic learning.
GenAI may improve the consistency and uniformity of feedback but in doing so it may not address individual students’ needs.
GenAI may remove some teacher biases but it introduces others.
Some studies show only small differences in quality between human and GenAI feedback. But there are nuances here that we need to pay attention to (see above).
The more mechanistic the feedback / assessment task, the better GenAI performs.
Using GenAI for feedback may be worth the trade-off for some in situations where class sizes are too high (something is better than nothing, seems to be the argument here). But also, using GenAI for such feedback may not save that much time, given how much oversight and individualization in prompting we need to provide.
Given the complexity and breadth of research on this topic, we should remember that just because it is now easy to automate feedback and assessment does not mean we know enough to do it well. The frictionlessness of GenAI, how you can do things that look good but aren’t backed up by any actual expertise or knowledge, is a problem not just for our students, but for us too.
What we value
As Marc Watkins has recently written, the question of GenAI, feedback, and assessment gets to the heart of our values as educators. If higher education is just a credential farm, then efficiently sorting students into rankings makes sense and by all means we might as well automate away. Most of us, of course, do not see education in this way.

I approach these questions as a long-time ungrader and equity-grader. Like Chris Gallagher, Asao Inoue, April Baker-Bell, Stephanie Westpucket and many others, I’m skeptical of assessment practices that reinforce hierarchies by rewarding normative performances. I’ve heard too many stories from students about how such practices warp their identities as writers. For Westpucket et al, feedback and assessment are already too rubric-oriented, too normative, too mechanistic; they impose a “mechanical uniformity” that seeks “to make humans perform like machines.”
Is this why faculty feel burdened and overwhelmed by feedback and assessment? Why assessment is often cited as the most hated part of our jobs?
It’s funny that we see assessment this way — as a mechanistic, impersonal judgement of student performance — when the root of the word is actually humble and human: it comes from the Latin, meaning “to sit beside.” We sit beside our students when we read their work, try to understand their thinking and consider how best to cultivate their capacities. When we encourage their effort. When we mentor them into new identities as writers, students, professionals. This is relational work at the heart of education.

Read this beautiful essay by Johanna Winant to glimpse a sense of what I mean. If we conceptualize feedback and assessment in this way, rather than as a mechanical matching of performance to rubric, might it feel less tedious?
But what about our teaching loads?
This idealized view of feedback requires working conditions that most of us simply don’t have. Writing instructors on some campuses (including SF State) can have up to 125 students per term, more than double NCTE recommendations. Giving feedback at this scale feels impossible. It’s an old, but very real, problem: NCTE’s How to Handle the Paper Load came out in 1979. Jeffrey Golub’s More Ways to Handle the Paper Load followed in 2005.
Over the years, as these titles suggest, we have innovated ways to lighten the load without compromising good pedagogy. This resource page from the U of Pittsburgh provides an overview of ethical time-saving methods. This website includes descriptions of portfolio grading, ungrading, and metacognitive feedback approaches, all of which I highly recommend. This post from Emily Pitts Donahoe has feedback/assessment strategies for large classes. I’ve also often recommended single-point rubrics as a time-savor for those who like more structure.
Commercially-manufactured feedback: coming soon to an LMS near you
Still, we may struggle to resist the onslaught: commercial AI products for teachers are coming fast and furious. Marketed as time-saving, they promise to free us from the burden of feedback and assessment. There’s Cograder, Gradescope, Chat GPT Zero (once an AI detection platform, now providing auto-grading), Magic School AI, which has contracts with several K-12 districts.
Canvas doesn’t yet have AI capabilities. But Instructure has partnered with OpenAI, so we can expect AI enhancements soon, including, perhaps, an AI function in speedgrader.
Last week, Anna Mills posted a direct appeal to AI companies, asking that they prohibit AI-enabled student shortcuts (cheating) within learning management systems. As companies rush to automate core aspects of our jobs, maybe we should issue a similar request: prohibit AI-enabled shortcuts that devalue teachers’ roles or outsource our work.
Which brings me to Brisk, a company created by “technologists, educators, and parents” whose aim is to “lighten workload for teachers” so they can spend more time “doing what they love - teaching, not administrative tasks.”
But Brisk’s website makes clear the opposite: it automates teaching rather than administrative tasks. It promises to provide feedback, create instructional materials, design assessments, write unit plans, generate targeted activities aligned with state standards, and write IEP and 504 plans.
With the Chrome extension, Brisk allows you to give student feedback directly into a Word or Google Doc. You can upload a rubric and set the parameters of the feedback (tone, content, types of question or suggestions). You can edit before you hit “comment” and Brisk will keep your feedback prompts, so you can easily reuse them.
I experimented with Brisk so you don’t have to (seriously, I recommend against using a tool like this because I don’t trust its data privacy practices, and I don’t like the assumptions it makes about our work). In my experiments, I created a few short faux-student reading-response drafts. I used the feedback prompt below.

How did Brisk do?
It summed up my faux-student’s main idea accurately, but when I limited it to 30-40 words to avoid overwhelming the faux-student, the quality declined: it identified a quote from an assigned reading as the main idea (it labeled this non-main idea as “the beating heart of your draft,” which suggests the sycophancy problem is alive and well). Plus, my faux-student showed a wobbly understanding of the quote, so the synthetic feedback missed the mark in that sense too.
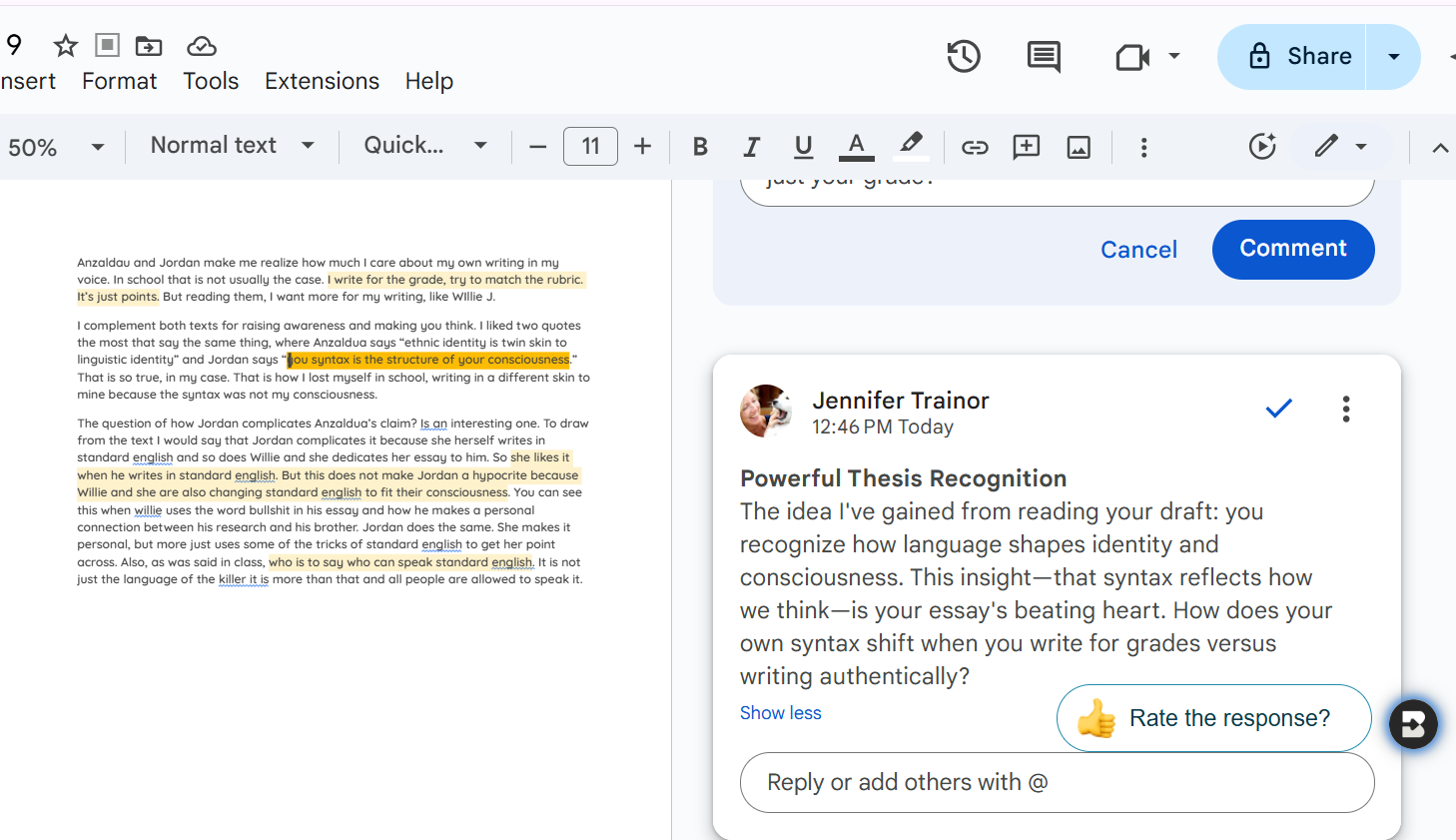
I prompted Brisk to ask questions to deepen the student’s analysis, and here it did okay. The questions were engaging and contextually on point. If a student used them, they would indeed deepen their analysis.
But when I showed my students some AI-generated “questions to deepen your analysis,” (using our enterprise AI platform and with full transparency with students), my first-year students told me they found the questions boring and unrelated to their drafts, even when I told them I thought the questions were pretty good. They preferred my questions to AI questions because, as one of them said, “it’s nice to know you are reading us.” Another said “I don’t think ChatGPT knows what questions real people have.” A few students said if they were going to use AI, they would simply have ChatGPT do the assignment, rather than ask it for questions to deepen their analysis. “It’s supposed to be time-saving,” one student said pointedly.
The Hallmark-card-ification of feedback
Student responses aside, I found aspects of Brisk’s feedback to be surprisingly good. But I also felt like my positive response was influenced by Brisk’s integration into Google Docs. Looking at synthetic feedback posted under my Google icon using Google’s familiar comment function gave me a stronger-than-usual sense that the synthetic text sounded like something I wanted to say.
As I experimented with this integration, I kept thinking about Hallmark cards, and what the Hallmark-card-ification of feedback might mean for us. It’s easier and faster to pick a card out from the drugstore than it is to write a poem and design a card yourself. Thanks to the juggernaut of Hallmark, we’ve come to accept if not embrace commercially manufactured sentiment. But are we ready for commercially manufactured feedback? Are students going to engage with feedback that has been endorsed but not created by their instructor, much like choosing a card and endorsing its message with your signature? I will confess: if you buy me a Hallmark card, there is a strong chance that I skip the greeting and go straight to the note you scrawled across the bottom of the card before signing it. I think students might do the same.
More worryingly: Will I notice the biases baked into commercially manufactured feedback, especially when that feedback is so seamlessly integrated into what is for me a highly personalized workspace? Would I pick up on places where AI missed the real beating heart of a student’s draft, given this deceptive integration? It’s worth repeating: technologies aren’t neutral; they shape us as we use them, as Ron Purser’s beautiful essay makes clear.
Does Brisk do better with a more structured, rubric-driven approach? I tried this a couple of ways. I used the AAC&U Value rubric for written communication and asked for feedback on one of my own Substack essays. Brisk gave me laudatory comments and accurately matched parts of my essay to the rubric criteria.
But the improvement suggestions were ridiculously generic: wordy versions of boilerplate comments such as “add detail” and “use topic sentences.”
Next I pulled two anonymous, already-public sample student essays off the internet. The first was a parody, written in a tongue-in-cheek manner. Brisk did not pick up on the parodic elements. It praised the writing as “lively” but gave low marks for not being academic without explaining this contradiction to the student.
The second fail was more egregious. The sample draft was from a community college placement website. I took the lowest scoring sample (the community college had placed the writer in a support course) and asked Brisk to use the AAC&U rubric to determine whether the essay was passing. After accurately noting some problems in the draft, Brisk passed the student in all categories. When I tweaked the prompt, it agreed that the essay did not meet the rubric’s benchmark criteria, but still nonsensically recommended a passing score. There are probably finer-tuned prompts that would get better results, but my point stands: Brisk is not the quick and easy solution to “administrative” tasks that it portends to be.
What about AI-assistance rather than automation?
There’s a world of difference between off-loading and load-sharing, between automating your feedback and using tools to make your feedback better or save you time. And as Tawnya Means and Andy Masley argue, cognition itself is not a finite resource. Automating one aspect of a task can open up space for creative thinking in another. Maybe that commercially-manufactured rhyme on the Hallmark card inspires you to write a long personal message to the recipient before you affix your signature. Maybe without the scaffold of the manufactured card, you wouldn’t have written a message at all, because the work of doing so was too hard.
To put this in Marshall McLuhan’s terms: Yes, we may amputate some cognition when we automate it, but we certainly also create space to amplify other creative/cognitive processes. Cognition and creativity, as Sarah Eaton has written, will always be present.
What might such load-sharing, AI-assisted feedback look like in practice? One of my colleagues uses our enterprise GenAI platform to turn his messy notes on a student’s project into student-facing feedback. Others have said that GenAI helps jumpstart their thinking or helps them analyze student work so that they know what to focus on. A tool like Brisk might be valuable in helping faculty create a template for feedback that merely needs to be tailored and reviewed. This won’t save a ton of time, but when you’re looking at 150 student projects, even a few minutes per student will add up.
Still, I worry. When you have 150 students, the temptation to just copy/paste the feedback rather than tailor and review it is probably going to be pretty high. Plus, given quality-control requirements, we might find ourselves spending even more time trying to engineer the right prompt and clean up the AI mess. Most importantly, if you use AI to jumpstart your thinking, are you overcoming the biases you bring to the task, as some claim, or are you absorbing more biases, caving to the normative and already-known?
There is a better way …

PAIRR is an AI feedback approach created by faculty at UC Davis. PAIRR stands for “peer and AI review and reflection.” The steps are simple: students get peer feedback; then, using an instructor-designed prompt, they get AI feedback. They review and compare the two sets of feedback, choose what to focus on, revise, and then reflect on the process.
Does this automate your feedback? No. Does it save you time? Maybe. Good peer feedback can save time because it improves the quality of the final draft, which can free us to engage with students’ ideas or provide a high-level overview of successes and next-steps. If you’re someone who tries to give both formative and summative feedback (guilty as charged), PAIRR can take the formative phase off your plate.
I like PAIRR for a number of reasons. It doesn’t outsource faculty feedback. It encourages student engagement with feedback, which is what matters most when it comes to learning. It gives students agency over AI outputs, and cultivates metacognition and critical AI literacy, as students identify inaccuracies, biases, and shortcomings.
Interestingly, PAIRR student surveys show that only 6% of students preferred only the AI feedback, but a sizable chunk -- 36% -- preferred peer only without the AI.

The researchers conclude: while technology may offer support, we should pay very close attention to students’ needs for “humanity” and “real feedback.”
I’ll wrap up on that human note: it’s end-of-term crunch time and I have feedback to give. How are you all doing out there? Let me know your thoughts!